

Interceptors! If you've delved into the more advanced workings of HttpClient, or if you came from AngularJS, these were one of the more frequently requested Angular features back when Angular first arrived. Most often used to deal with authentication or possibly caching, and then most often through a third party library, interceptors can actually offer quite a bit of power when it comes to managing the flow of data to and from your APIs.
If you are a beginner or intermediate Angular developer, despite the "Advanced" nature of the validators that will be covered in this article, I strongly encourage you to STAY and keep reading! We progress through the process of starting with a simpler interceptor and eventually refactor it, step by step, into a more advanced interceptor capable of doing things you may never have thought possible. This article is progressive, so you do not necessarily need to read it all on one sitting!
Recent Interceptor Excursions
Here at Briebug, we have had to delve into the furthest reaches of interceptors in some of our recent projects. To solve our client's needs, in our most recent use case, we had to resort to using an interceptor to coordinate multiple http requests with each other and do so in such a manner that it maintained optimal performance for all requests.
The initial approach we took was fundamentally flawed, based on an incorrect assumption about the nature of the RxJS stream used within the interceptors. Upon subsequent reevaluation of the approach, after the solution did not work properly in the intended use case, some truly innovative functionality emerged to provide the proper behavior in an efficient manner.
Reactive Interceptor for Reactive Validators
The interceptor we will be covering in this article goes hand in hand with the validators in our companion article on advanced reactive angular validators. The job is to cache results from a third-party, rate-throttled and request-limited zip code API, and do so effectively with concurrent requests. Read the article on the validators to get the rest of the story.
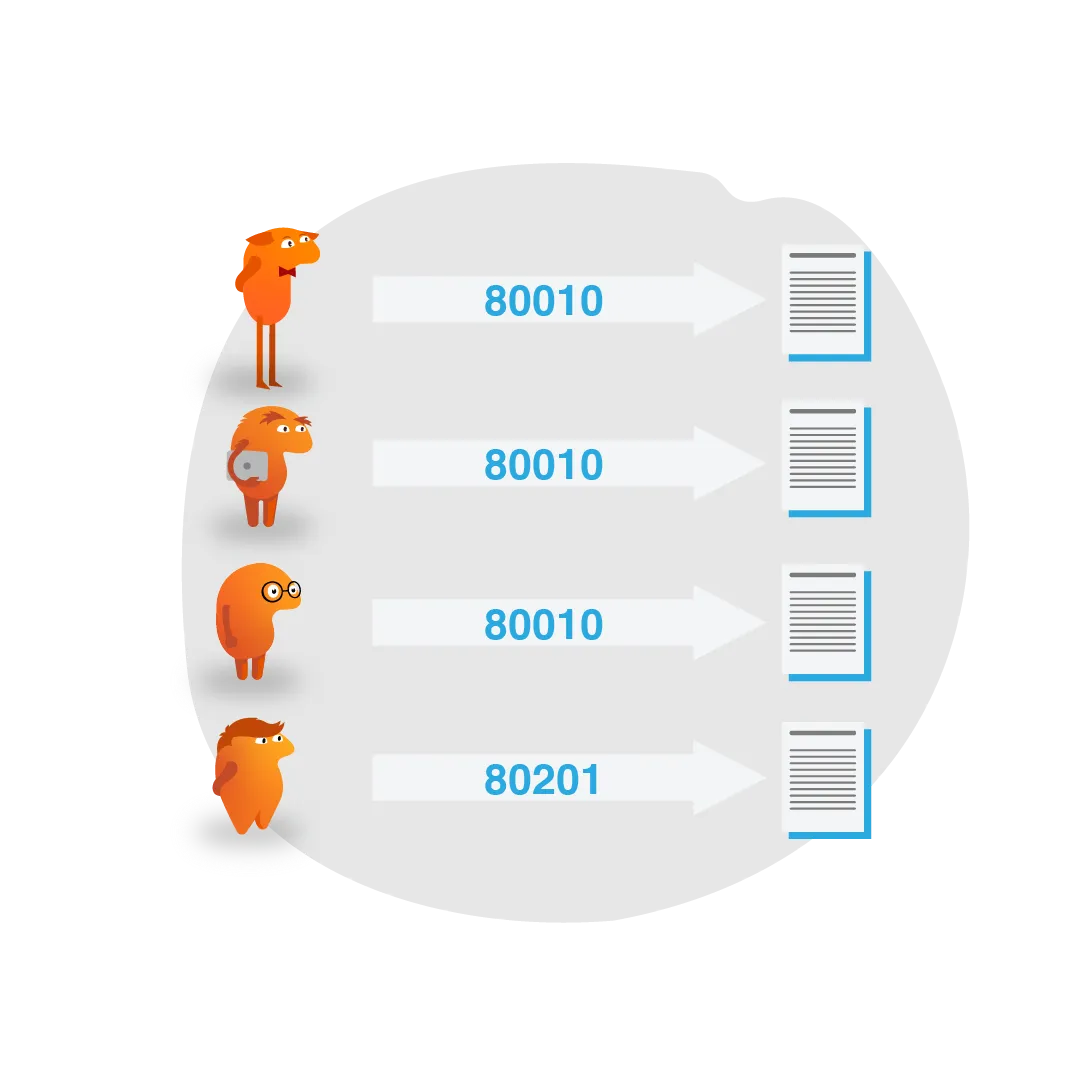
A Naive Interceptor
To support the use of the ZipCode API for our validators, we needed an interceptor that would cache results from this API. For any given zip code, the chances of the results changing in any shorter timeframe were remote: zip code details rarely change even over the very long term. So we made the assumption that we could cache forever, or at least until app restart/refresh, and therefore only request information for any given zip code just once.
Our initial attempt was rather naive; simply trying to look for a zip code result in a cache and return that, otherwise make the actual request to the ZipCode API to get the data and then cache it. So we created a class that contained a private cache and performed this very naive caching strategy:
To avoid slowing down any non-zip code API calls, the interceptor first checked to see if the path contained the necessary /zip-code/ api path. Otherwise it simply passed the call through. Otherwise, any successful response from the API was cached.
Void 0
As a small side note, the use of void 0 here is simply a way of maintaining a consistent type through a ternary. When calling another function or performing a basic assignment expression inline, within the context of an operator that expects void to be returned in particular, void 0 is a type-correct way of "ignoring" one of the ternary branches.
Ignorant Ignorance of Errors
Upon the initial review of our interceptor, before even putting it through its paces in a real-world situation, the first thing we noticed was that error responses from the zip-code API were not being properly handled. Series 400 errors from the ZipCode API were, in fact, valid responses given that a 404 represented an unknown zip code not in the global database of all zip codes. As such, these error responses would need to be cached as well in order for the interceptor to perform one of its key jobs properly: limit the number of requests to the api, of which we had a limited number allowed (notably in the free tier!)
We decided to expand the interceptor to support caching error responses as well. Initially, these were just added to the existing ZipCodeCache structure. However, that revealed a nuanced behavior of interceptors. Errors with HttpClient propagate through the error "channel" of an RxJs stream. If you have some skill with RxJs, you should know that for every stream there is a primary data or "next" channel, the "error" channel and the "completion" channel. Each kind of notification, in effect, is handled on their own channels when notifications are "dematerialized" (see the materialize and dematerialize rxjs operators for more.)
We realized that caching errors in the normal result cache and returning them like normal results wasn't going to work. We needed to throwError the error results and further, where successful results were of type HttpEvent<T>, error responses were of type HttpErrorResponse.
Adding Error Handling
To resolve the discrepancy between handling successful queries to the ZipCode API, and handling error responses, we added another cache for errors and explicitly checked for the type of the cached result in order to direct those cached results to the proper channel in the request stream:
With this, we started testing our interceptor with some real-world test cases; utilizing a form that was applying the previously mentioned zip-code validators from our companion article. And that was when we realized the complexity of the problem we faced was much greater than we had initially anticipated.
Multiple Discrete and Independent Streams
The particular problem we were facing with the ZipCode API was two-fold: there was rate limiting, which allowed only N number of requests per unit time, and there was total request limiting, which allowed only M number of requests per month. The nature of Angular Form validators is that they are applied for every change to the form. When patching a form with a data model, each property from that model that is patched into the form causes a validation cycle, and with a complex form, dozens of validation cycles can run in microseconds.
The goal with caching the ZipCode API results was to prevent spamming the api during fast form validation cycles, which could easily hit rate limiting issues. Further, all that spamming would unnecessarily burn up some of the total allowed requests per month to the API. We needed to cache the results in such a manner that we PREVENT spamming the API calls and that, as it turned out, was not as easy as we originally assumed.
Discrete and Independent Requests
When writing an Angular Http Interceptor, it is easy to lose sight of the fact that the stream you are working with is not a stream of all the http requests made in the application but the stream that represents a SINGLE, DISCRETE request! Each Http call made with HttpClient creates a stream and that stream, in fact, is a stream of HttpEvent<T> objects. There are a number of events that propagate through the Http client streams representing the various different stages of creating, initiating, handling and closing out and handling errors of an HTTP request to a remote API.
Each stream, however, is independent of each other; which means if you need to coordinate across http streams, you will have to determine a way of doing that yourself as such functionality is not built into the Angular Http Interceptor framework.
Initial Incorrect "Solution"
Not initially grasping that each Http interceptor handles each request independently, our first naive solution to the problem was to try and use concatMap in our existing code, rather than switchMap, to try and queue up requests if they were to the ZipCode API:
This, of course, did not work as we were not queueing up separate http requests here. We were still working with a SINGLE request and simply queuing up different HttpEvent<T> values on the stream. This is something we knew, and yet, didn't fully grasp relative to the need we had to synchronize multiple distinct requests.
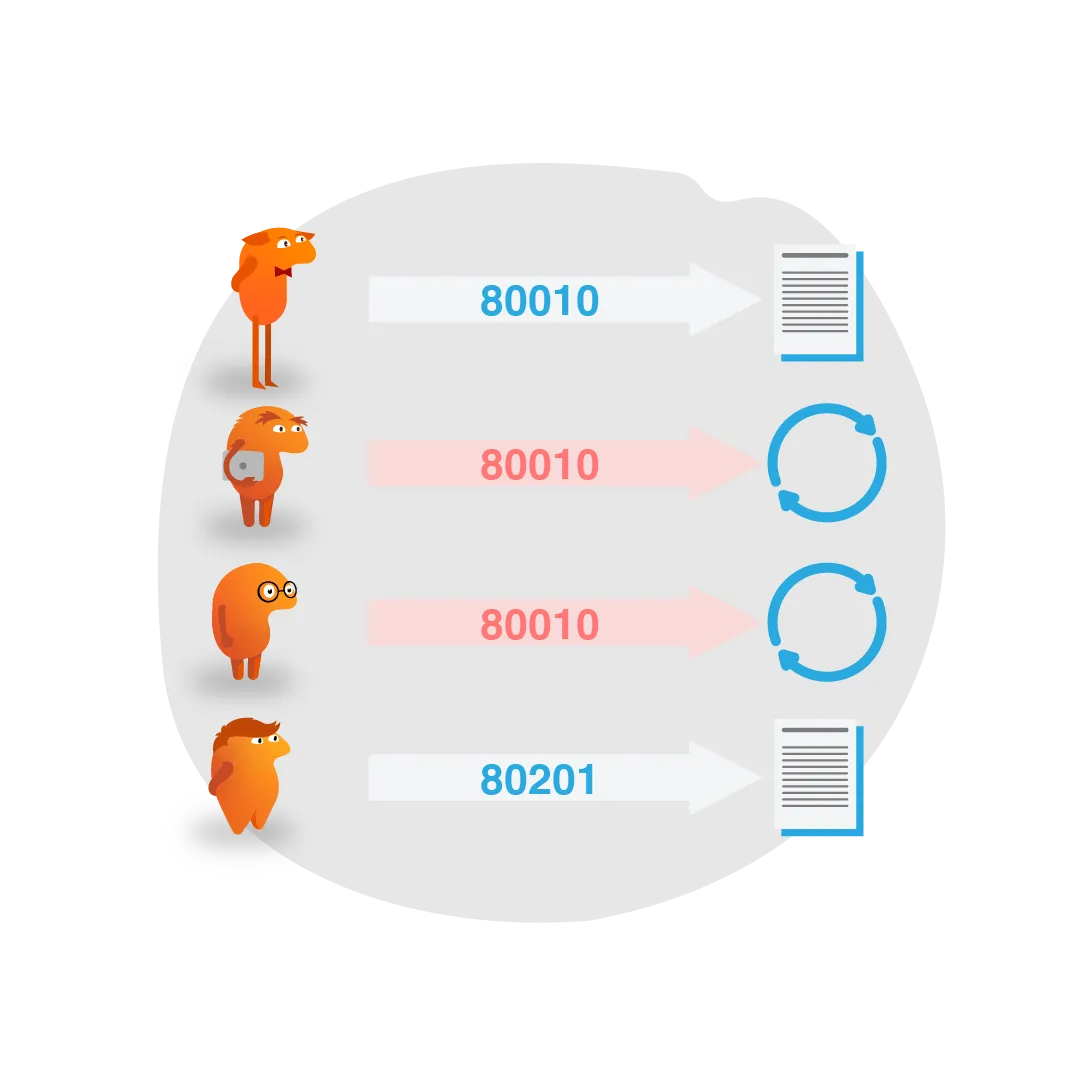
Cross-Request Synchronization
Solving the problem of synchronizing separate http requests was clearly more challenging than our initial assumptions. An Angular Http Interceptor handles the event stream of a single request, so we needed another way to synchronize across requests. Since we wrote our code reactively with RxJs, we have all the power of RxJs at our fingertips to solve this problem.
We set out to define a mechanism of synchronizing multiple concurrent http requests, to a given url, using a custom RxJs operator. We needed the ability to block a particular request from continuing if another request to the same url was already in progress. We also wanted to support allowing pending requests to wait, only up to a certain maximum amount of time, after which the requests would be abandoned.
While JS is single-threaded, it is asynchronous. And once the initial request is made to a remote server, the next event in the JS event queue will be handled immediately. That allows multiple concurrent requests to the same endpoint to be initiated together, meaning we effectively spam the ZipCode API during fast form patching validation cycles. We decided to use a simple locking mechanism to effectively "lock" the url. Once the first request locks the url (which can be acquired easily due to JS' single-threaded nature) then other requests would check if the lock is held and, if so, fall into the delay/retry loop. If the lock was not yet held, it would be acquired and the request would go through.
The synchronizeOn Operator
Our new RxJs operator, being a synchronization operator, was called synchronizeOn. This operator accepted three functions:
- A getLock function that allowed the operator to check if the lock was already held
- An acquireLock function that allowed the operator to acquire the lock for itself
- A nextDelay function that allowed the operator to retrieve the next delay in milliseconds
These three functions allow the operator to externalize certain details of the locking mechanism to the consumer, and allow customization of what the lock is actually relevant to, as well as how many delay cycles there are, as well as how long each delay is. The nextDelay function can return a falsy value to end the delay cycles, which causes an error to be thrown. The locking functions are provided the value currently moving through the stream, which may be used as part of the locking mechanism, or not:
Error Flow and Retries
The synchronizeOn operator has to make very careful use of errors to control flow and retries to function properly. Initially, switchMap was used with of and throwError. This original solution did not actually synchronize properly; we believe due to how the retryWhen and delayWhen operators work. It tries to retry the stream that feeds into it, and when switchMap or any other stream mapper was in use, retries did not start back on the right stream. The switched stream, rather than the original source stream, was retried.
To resolve this problem, we ended up resorting to using a bit of imperative code, which is not generally ideal when your aim is to have a completely functional code base. However the use of the imperative throw within a normal map operator ensured that the retried stream was the correct one:
A new custom operator could be created to encapsulate this non-switching throw behavior. So we put together a throwIf operator to encapsulate the functionality where if the predicate evaluates true, then it throws:
Which then turns our operator into the following:
With that, our operator was complete! It was time to turn our attention to synchronizing requests to the ZipCode API.
Unlocking locks during synchronization
While our synchronizeOn operator will check if a lock can be acquired, and acquire it when it can be, it did not handle releasing the lock. Releasing the lock would occur on demand at the appropriate stage of processing the requests in our interceptor. However, since we were working with an RxJs stream, we needed to make sure it occurred for the error channel as well.
To support this in a clear and concise manner, another operator was created: synchronizeOff. This operator was responsible for dematerializing the RxJs stream and handing the notification back to the caller where the lock, an externally handled factor, could be released via whatever mechanism was appropriate. The operator itself is quite simple:
The materialize operator is an uncommon one but has its uses. In our case, we wanted to make sure that unlocking occurred regardless of whether the stream was emitting the next value, emitting an error or completing. Materialization coalesces all of these separate "channels" within the stream into a Notification object. This object exposes the metadata about the emission moving through the stream, as well as the value or error. The releaseLock callback can then handle the notification as it sees fit to release the lock properly.
The name here was ultimately chosen to make sure that the relationship to synchronizeOn was very clear. Originally it was called releaseLock which, while appropriate, was also a bit arbitrary and didn't really expose the direct and necessary association with synchroniseOn.
Refactoring the Interceptor
With our new synchronization operator in hand, it was time to re-think how our interceptor was going to work. First off, we decided that we could make the decision about whether to do anything with the request at all sooner in the process. With the original interceptor, we started off grabbing the result cache then, later, decided whether the request should be handled by the interceptor or not. However, the decision of which path to take really should have been made first before accessing the cache or anything else. Once the determination was made that the requested resource was a zip code, we would then synchronize requests, and then either pull the requested response from the cache or make the request and cache the response:
Our newly refactored interceptor is improved on the old in a couple of ways. First, it follows a more logical flow checking to see if any work needs to be done first and, if the requested url is not a ZipCode API url, then the request is simply handled as-is. Otherwise, we synchronize only requests to the ZipCode API and the rest of the logic to return cached values or cache responses is largely the same as it was before. The new synchronizeOff operator was applied in a couple of locations to ensure that any acquired lock is properly released.
Registering and Testing
Now that we had implemented what should be an effective interceptor, it was time to put it to use. The criteria for success were as follows:
- appropriately limit the number of requests to the ZipCode API
- ensure that the cache was maximally used as often as possible
- given zip code information doesn't change much, each zip code only really needs to be queried once!
- ensure these are applied concurrently across all requests to the ZipCode API
Registration
In order to apply the interceptor to our requests, it first needs to be registered. That is a very strait forward process with Angular. We simply need to provide it using the HTTP_INTERCEPTORS built-in provider in our application module:
Make sure to set the multi property for this provider to true as multiple interceptors can be registered this way and all of them will be applied.
Testing with Validators
Finally, we tested the interceptor simply by using the Zip Code Validator we created, which can be found in our companion article here. First off, we commented out the interceptor registration. We then created a basic address form with a zip, city and state, applied the validators, patched the form with an object that contained basic address data and kept an eye on the network requests.
Initially, as originally, we noted multiple concurrent requests to the ZipCode API. As the form is patched, each control that has a value set kicks off validation of the entire form, so depending on just how many of the zip code validators are in use (i.e. there can be one on the zip code, as well as on the city and state) you may find that half a dozen or so requests or more are made.
After uncommenting the interceptor registration, further testing indicated that each zip code validation was in fact only being requested from the ZipCode API once. Until a full refresh of the app, at which point the in-memory only caching of the interceptor was cleared. Success!

Adding Configurability
Our interceptor was almost done, however there was one small nagging aspect that kept glaring back at us: which routes to intercept were hard-coded! For our initial few passes this was fine, until we actually achieved proper functionality. Once the interceptor started working properly, we wanted to make it more configurable so it could be used to cache calls to other APIs besides the ZipCode API.
This was a relatively trivial problem to solve: provide a list of patterns that should be matched against the url and if any of them passed then the interceptor would cache results for those routes. To make this easy to handle from an end-developer standpoint, we decided to add a new injection token that could be used to configure the interceptor.
The configuration would be a simple object with one property, matchingRoutes, that would be an array of strings or RegExp objects. If a string, then the route must simply include that string, if a RegExp then the route must match that expression. Some general refactoring of our interceptor was necessary, and we included a name change to a more general purpose name of PreemptiveCachingInterceptor:
With our new configurable implementation in hand, we can add configuration for which routes we wish to apply this caching for in our app module:
And with that, our interceptor was capable of caching ZipCode API requests, as well as any request for lookup data on our local API, and any other potential routes down the road.
Improving Error Handling
As a final modification before we called our interceptor complete, we needed to handle error responses better. In its initial form the interceptor cached any and all errors, however this could mean that non-input related errors, like server errors, would also be cached when they shouldn't be. This modification was simple: simply ensuring that no 500-series HTTP error was cached. Further, it made sure that the only 400 series errors that were cached were those related to otherwise correct (but not necessarily valid) requests. This included 400 and 404, as well as 405 and 406 but no other 400-series HTTP errors. Auth errors such as 401 and 403, as well as timeout errors 408, should be retried.
First, a new map of allowed error codes to handle was created:
This map was then used to determine, when an HttpErrorResponse was received, which status codes could be cached:
Since the map returns true for any allowed status code and undefined (false) for any other, this simple map is a highly effective gating mechanism for easily and simplistically determining which error responses to cache.
Cross-Stream Flow Control!
With that, our rather advanced Http interceptor capable of cross-stream (cross-http request) flow control was complete. While our initial attempts made some naive and incorrect assumptions about Http interceptors, once we actually acknowledged what we already knew, that the interceptor was handling each request stream independently, we were able to devise a purely reactive solution to the problem.
The synchronizeOn operator should also provide an example of how to leverage RxJs to create new operators with very powerful capabilities, using simple tools like existing operators that you should already be familiar with if you already use RxJs. Note that, unlike many custom operator examples that rely on imperative code and complex nested functions that manually create and manage new Observables, our custom operator instead used the "unbound" pipe operator imported from rxjs and none other than existing and familiar operators like map, switchMap, retryWhen and creators like throwError.
Need Support With a Project?
Start experiencing the peace and security your team needs, and continue getting the recognition you deserve. Connect with us below.